
En un mundo donde la conexión no conoce fronteras, la localización se ha posicionado en el centro de las estrategias empresariales globales. Más allá de la mera traducción, es el arte de crear experiencias que resuenen en diferentes idiomas, culturas y mercados.
Hoy nos adentramos en el núcleo de la adaptación lingüística para descubrir dos técnicas transformadoras: la eliminación de palabras vacías (stop words) y la extracción de terminología. Basadas en el Procesamiento de Lenguaje Natural (NLP), estas herramientas son los pilares para construir arquitecturas de localización escalables y eficientes.
El Gran Reto de la Localización Moderna
Localizar va mucho más allá de traducir texto; implica ajustar formatos, estilos y tonos para que el producto final parezca nativo, aumentando la usabilidad y evitando errores culturales.
Uno de los mayores retos de la ingeniería de localización es procesar volúmenes masivos de datos. El texto puede provenir de código fuente, interfaces de usuario (UI), bases de datos o material de marketing. Para gestionar esta complejidad, recurrimos a la automatización mediante NLP.
¿Por qué eliminar las “Stop Words”?
Las palabras vacías o stop words son términos muy comunes (como “y”, “el”, o “para”) que estructuran las frases pero no aportan información clave sobre el contenido. En el procesamiento de datos, estas palabras actúan como “ruido”.
Eliminarlas antes de ejecutar tareas automatizadas reduce la complejidad de los datos. Por ejemplo, si queremos crear un glosario analizando la frecuencia de las palabras de un manual técnico, filtrar primero las palabras vacías nos garantizará obtener únicamente vocabulario de valor.
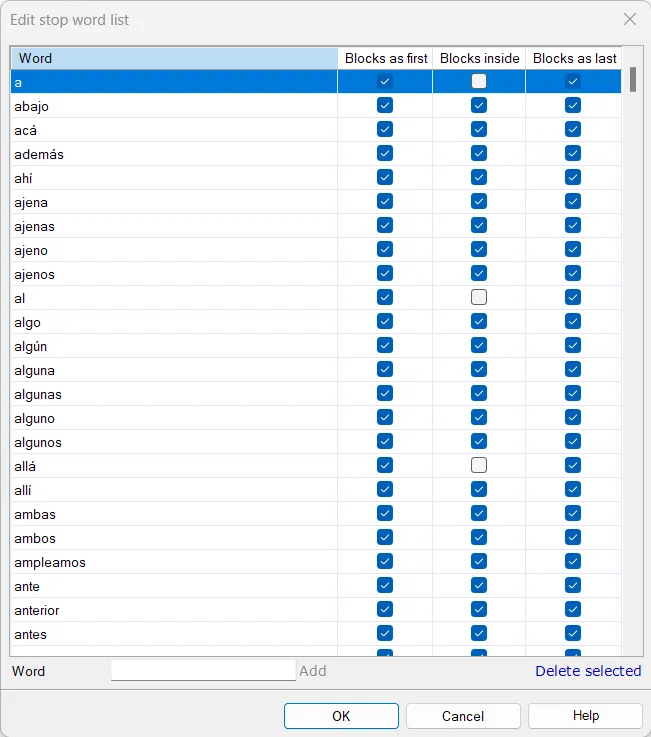 Configuración de Stop Words en memoQ
Configuración de Stop Words en memoQ
La Magia de la Extracción Terminológica
La extracción de terminología es el proceso automatizado de identificar palabras o frases que representan conceptos clave dentro de un dominio específico.
En nuestro sector, esto permite a ingenieros y traductores:
- Gestionar Conceptos Clave: Extraer candidatos a términos del código fuente para construir glosarios sólidos antes de empezar a traducir, garantizando la coherencia.
- Optimizar Búsquedas: Enriquecer las bases de datos terminológicas (TB) con sinónimos extraídos por contexto.
Casos de Uso Reales
- Localización de Software: Una empresa escanea su UI para generar un glosario base con las funciones principales de su producto antes de enviarlo a los traductores.
- Traducción Médica: Un traductor extrae la terminología altamente especializada de un ensayo clínico para validarla en bases de datos médicas antes de empezar a traducir.
- Adaptación Cultural: Extracción de entidades geográficas y culturales de una campaña turística para verificar cómo se deben adaptar estilísticamente en diferentes mercados.
Herramientas del Oficio
Existen diversas herramientas que facilitan este proceso:
- scikit-learn: Una popular librería de Python para Machine Learning. Su clase
CountVectorizerconvierte colecciones de texto en matrices, permitiendo aplicar análisis de n-gramas y filtros de palabras vacías. - RAKE: Un algoritmo rápido y ligero que particiona el texto utilizando delimitadores y listas de stop words, puntuando las palabras clave según su frecuencia y coocurrencia.
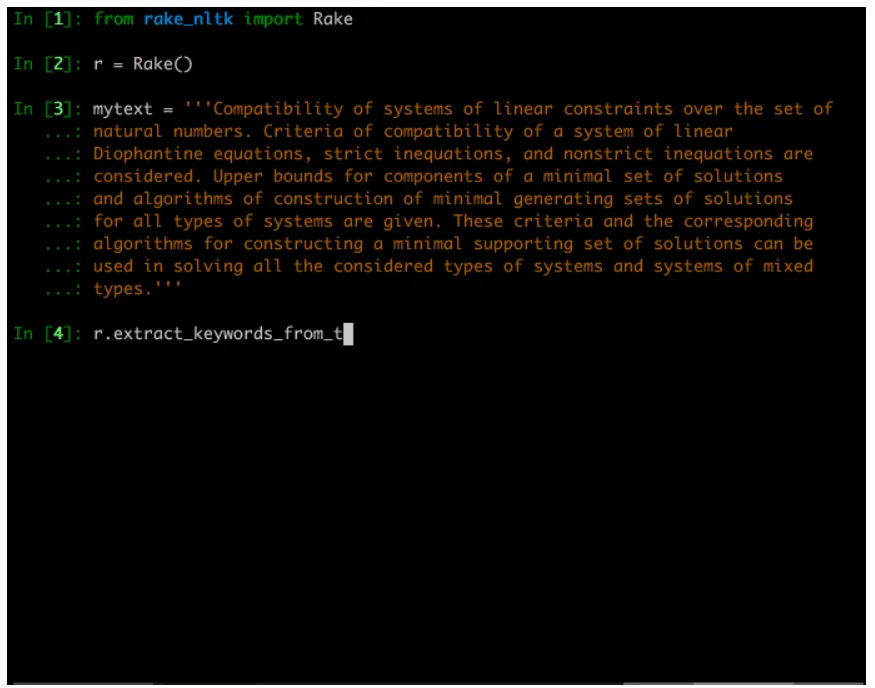 Algoritmo RAKE en acción
Algoritmo RAKE en acción
Paso a Paso: Extracción de Términos con Okapi Rainbow
Okapi Framework es una suite de localización de código abierto, multiplataforma y gratuita. Su aplicación de escritorio, Rainbow, cuenta con un Pipeline de Extracción de Términos que utiliza análisis estadístico y anotaciones.
A continuación, te explico cómo automatizar la extracción de términos:
1. Descarga Okapi Framework: Asegúrate de tener Java instalado. Okapi es portable, por lo que solo tienes que descomprimir la carpeta y ejecutar las aplicaciones.

2. Inicia Rainbow: Abre la aplicación y crea un nuevo proyecto (File > New Project).
3. Añade tus archivos: Arrastra los archivos originales. Para este ejemplo, usamos un archivo de MS Word (Sample_EN-US.docx) del sector mecánico.

4. Verifica los filtros: Asegúrate de que Rainbow usa el analizador correcto (ej. OpenXML para archivos de Office). Formatos como XML o XLIFF soportan anotaciones terminológicas nativas que mejoran radicalmente la precisión.
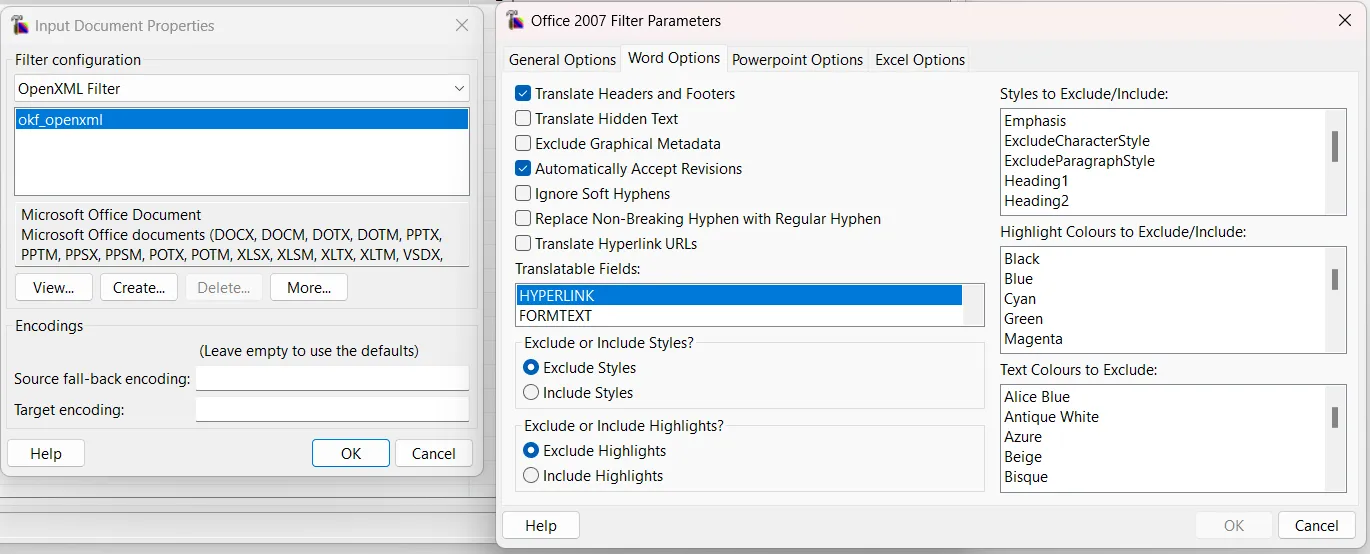
5. Accede a la utilidad: Ve a Utilities > Term Extraction....
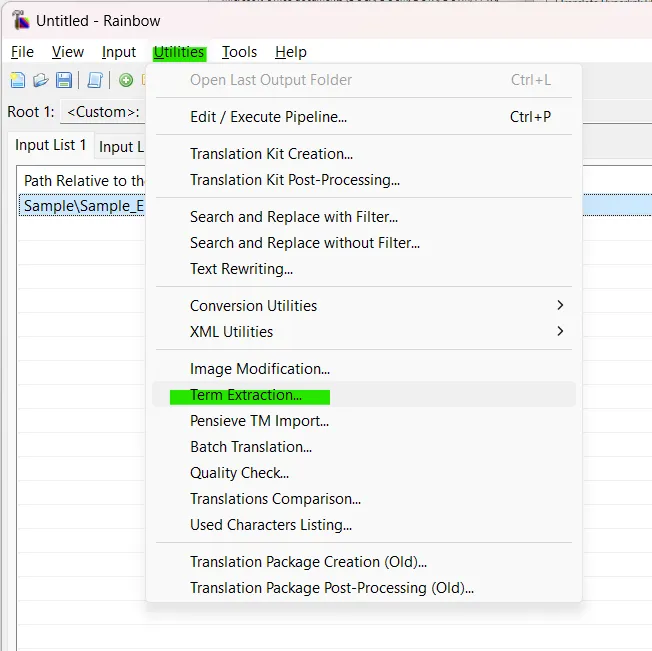
6. Configura los Parámetros: Define las reglas de extracción. Puedes filtrar por longitud de palabras, frecuencia mínima de aparición y añadir tus propios archivos de texto con stop words personalizadas.
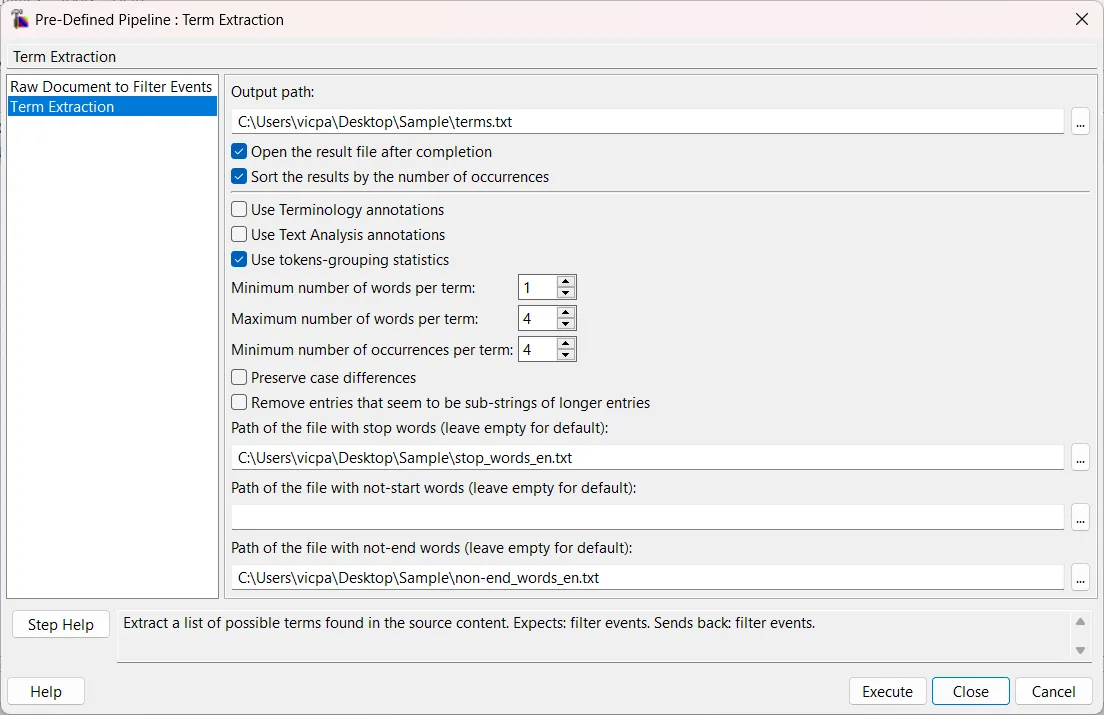
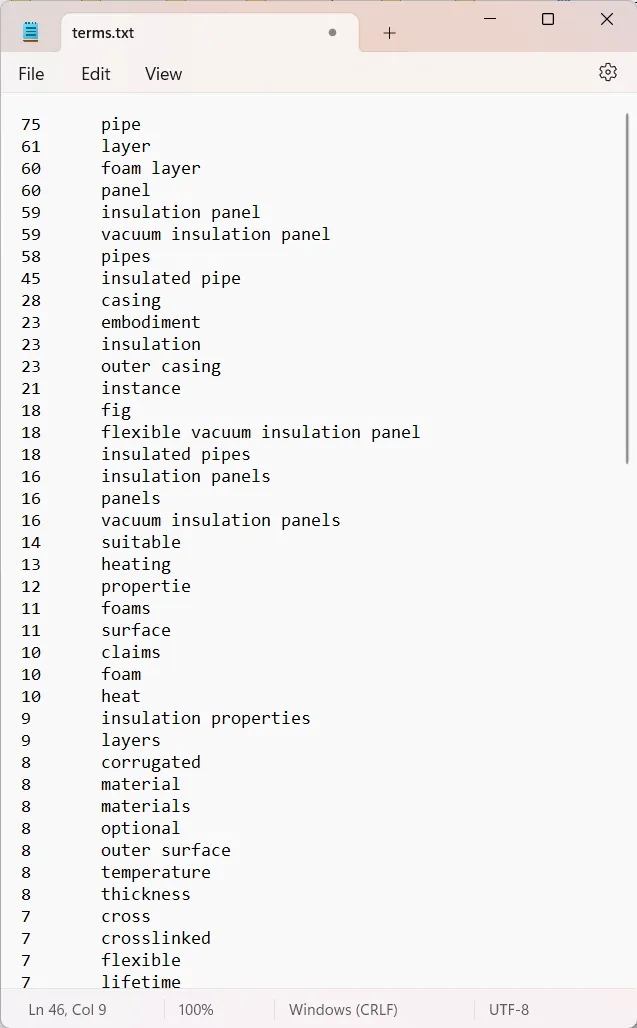
7. Ejecuta: Lanza el proceso. Rainbow generará un archivo de texto separado por tabulaciones con una lista limpia de candidatos a términos y su número de repeticiones en el texto.
Uniendo Traducción y Tecnología
Con esta lista en tu poder, puedes refinar la terminología de tu proyecto, crear un glosario pulido en Excel y subirlo directamente a tu herramienta CAT (memoQ, Trados, etc.).
En el dinámico panorama actual, técnicas como la eliminación de stop words y la extracción de terminología son indispensables. Okapi Framework es el ejemplo perfecto de cómo integrar tecnología y experiencia humana, demostrando que la localización moderna no va solo de traducir, sino de construir sistemas automatizados y escalables.
